Gitea
Gitea is an open source Github-lookalike written in
Go. Building Gitea from source is straightforward; the output is a single
executable gitea. Pre-built binaries and Docker images are also
available.
Once configured appropriately, gitea runs a HTTP server, which
provides the Github-ish user interface, and a built-in SSH server, which is
used for synchronizing Git repos.
In Pharo, Iceberg works with a locally running Gitea just like it works with Github.
I've been using Monticello for version control of my little tools. Monticello works when requirements are simple. But some of the tools have grown enough to need a VCS with good branching and merging capabilities.
Tags: DevOpsTelemon: Pharo metrics for Telegraf
In my previous post on the TIG monitoring stack, I mentioned that Telegraf supports a large number of input plugins. One of these is the generic HTTP plugin that collects from one or more HTTP(S) endpoints producing metrics in supported input data formats.
I've implemented Telemon, a Pharo package that allows producing Pharo VM and application-specific metrics compatible with the Telegraf HTTP input plugin.
Telemon works as a Zinc ZnServer delegate. It produces metrics in the
InfluxDB line protocol format.
By default, Telemon produces the metrics generated by
VirtualMachine>>statisticsReport and its output looks like this:
TmMetricsDelegate new renderInfluxDB
"pharo uptime=1452854,oldSpace=155813664,youngSpace=2395408,memory=164765696,memoryFree=160273136,fullGCs=3,fullGCTime=477,incrGCs=9585,incrGCTime=9656,tenureCount=610024"
As per the InfluxDB line protocol, 'pharo' is the name of the measurement, and the items in key-value format form the field set.
To add a tag to the measurement:
| tm |
tm := TmMetricsDelegate new.
tm tags at: 'host' put: 'telemon-1'.
tm renderInfluxDB
"pharo,host=telemon-1 uptime=2023314,oldSpace=139036448,youngSpace=5649200,memory=147988480,memoryFree=140242128,fullGCs=4,fullGCTime=660,incrGCs=14291,incrGCTime=12899,tenureCount=696589"
Above, the tag set consists of "host=telemon-1".
Here's another invocation that adds two user-specified metrics but no tag.
| tm |
tm := TmMetricsDelegate new.
tm fields
at: 'meaning' put: [ 42 ];
at: 'newMeaning' put: [ 84 ].
tm renderInfluxDB
"pharo uptime=2548014,oldSpace=139036448,youngSpace=3651736,memory=147988480,memoryFree=142239592,fullGCs=4,fullGCTime=660,incrGCs=18503,incrGCTime=16632,tenureCount=747211,meaning=42,newMeaning=84"
Note that the field values are Smalltalk blocks that will be evaluated dynamically.
When I was reading the specifications for Telegraf's plugins, the InfluxDB line protocol, etc., it all felt rather dry. I imagine this short post is the same so far for the reader who isn't familiar with how the TIG components work together. So here are teaser screenshots of the Grafana panels for the Pharo VM and blog-specific metrics for this blog, which I will write about in the next post.
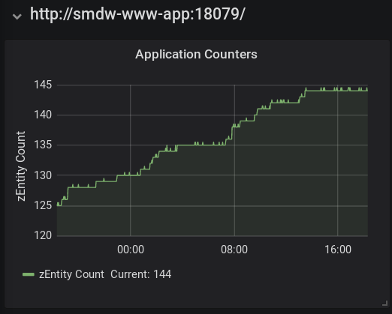
This Grafana panel shows a blog-specific metric named 'zEntity Count'.
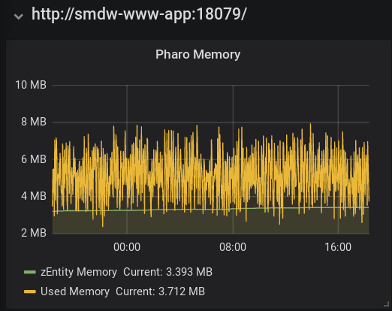
This next panel shows the blog-specific metric 'zEntity Memory' together with the VM metric 'Used Memory' which is the difference between the 'memory' and 'memoryFree' fields.
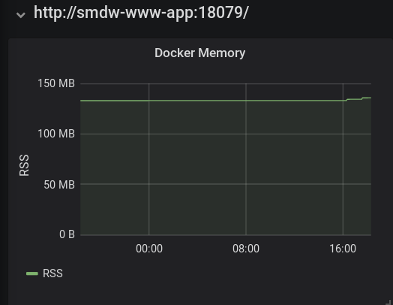
This blog runs in a Docker container. The final panel below shows the resident set size (RSS) of the container as reported by the Docker engine.
TIG: Telegraf InfluxDB Grafana Monitoring
I've set up the open source TIG stack to monitor the services running on these servers. TIG = Telegraf + InfluxDB + Grafana.
-
Telegraf is a server agent for collecting and reporting metrics. It comes with a large number of input, processing and output plugins. Telegraf has built-in support for Docker.
-
InfluxDB is a time series database.
-
Grafana is a feature-rich metrics dashboard supporting a variety of backends including InfluxDB.
Each of the above runs in a Docker container. Architecturally, Telegraf stores the metrics data that it collects into InfluxDB. Grafana generates visualizations from the data that it reads from InfluxDB.
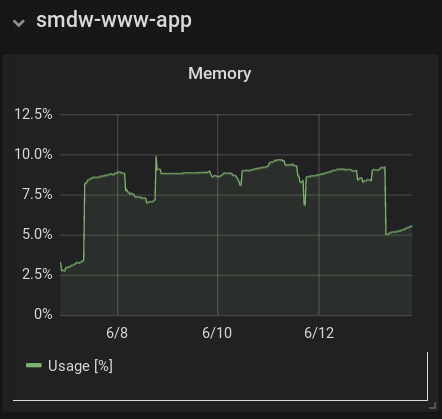
Here are the CPU and memory visualizations for this blog, running on Pharo 7 within a Docker container. The data is as collected by Telegraf via querying the host's Docker engine.
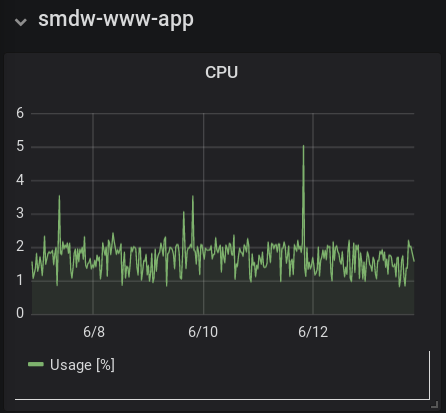
Following comes to mind:
-
While Pharo is running on the server, historically I've kept its GUI running via RFBServer. I haven't had to VNC in for a long time now though. Running Pharo in true headless mode may reduce Pharo's CPU usage.
-
In terms of memory, ~10% usage by a single application is a lot on a small server. Currently this blog stores everything in memory once loaded/rendered. But with the blog's low volume, there really isn't a need to cache; all items can be read from disk and rendered on demand.
Only one way to find out - modify software, collect data, review.
Tags: DevOps, DockerIceberg and SSH keys
On a laptop that I've just rebuilt recently, I created and have been using an ED25519 SSH key pair, including with Github. Iceberg doesn't work with it though, throwing the error 'LGit_GIT_ERROR: No ssh-agent suitable credentials found". This is because Iceberg uses libgit2, which uses libssh2, which apparently doesn't support ED25519 keys. Created a new RSA key pair, registered it with Github, and Iceberg works.
- OS = Linux Mint 18.1
- Pharo image = 60510-64
- Pharo VM = pulled from GH opensmalltalk-vm today and built on said laptop
Proof of Concept: FileTree and Fossil
While putting up PasswordCrypt on Github, I was working with its local FileTree repository. I found the workflow cumbersome - committing in Pharo causes untracked files and so on as seen by Git, which had to be resolved by hand, followed by 'git commit' and 'git push'. I know that tools like GitFileTree and Iceberg are meant to smoothen the workflow. I also know that I don't know Git well at all.
OTOH, I use multiple computers - a main Linux/Windows workstation, a Mac, and a small laptop for tinkering on the go - and keeping all my mcz files in sync on these computers is getting to be a chore.
I am a fan of Fossil. In addition to being a
DVCS a la Git, Fossil comes with a wiki, ticketing system, simple
HTTP-based networking to sync repositories, and other good stuff.
This blog's content is managed using Fossil.
However, using Fossil in place of Git to manage FileTree repositories at the directories/files level still requires the 2-step workflow: commit in Pharo, fix up the changes with Fossil, commit in Fossil.
So I wrote a simple integration of FileTree with Fossil.
At the operating system command prompt, init a new Fossil project:
os% mkdir ~/repo
os% cd ~/repo
os% fossil init myproject.fossil
project-id: 3c05c3016eeabf8e87816ee218c6a86d3c87b950
server-id: ff42bc86dba1a26b1d94b64685f7c09d02581617
admin-user: laptop-user (initial password is "1fe2ff")
Open the repository:
os% mkdir ~/myproject
os% cd ~/myproject
os% fossil open ~/repo/myproject.fossil
In a fresh Pharo 6 image - I used v60411 - install FossilFileTree:
Metacello new
baseline: 'FossilFileTree';
repository: 'github://PierceNg/FossilFileTree';
load.
Write code in Pharo. Open Monticello Browser. Add a "fossilfiletree" repository, using ~/myproject as the directory. Save to said repository from within Monticello Browser. Done.
To check what Fossil got, run 'fossil status' in ~/myproject. The last line 'comment: ...' contains the in-Pharo commit message.
And now I get to use Fossil to keep my FileTree repositories in sync among my computers.
Notes:
- I basically copied GitFileTree's use of OSSubprocess to call the Fossil executable.
- Tested on Linux with recent Pharo 6 only. I tried to install on a Pharo 5 image, but the installation hung somewhere.
- The above is all this thing does. For all other Fossil-related operations - clone, sync/push/pull - use Fossil.
- Not written any test.
Logging libraries for Pharo 5
Below are the logging libraries that I've found for Pharo/Squeak:
- Log4s
- Nagare
- OsmoSyslog
- Syslog
- SystemLogger
- Toothpick
Log4s for Pharo is a port of the VA Smalltalk port of the popular Java logging framework Log4j. I installed it from Pharo 5's catalog browser. 206 of 207 tests passed, with 1 failure. None of the classes is commented, although being a port of Log4j, the Java documentation should work as reference.
Nagare is a "flexible logger which connects to Fluentd." It was written to run on VisualWorks, Squeak and Pharo. I installed it from the catalog browser. None of the classes is commented. No test suite. Documentation remains on the Google Code project wiki.
OsmoSyslog is a "log backend/target to use system syslog." AGPLv3+. I stopped there.
Syslog is an RFC5452 Syslog UDP client. I installed it using a Gofer snippet. It loads OSProcess. Every class has a class comment. Test suite has four tests. Because I have OSSubprocess in the same image I did not attempt to run the tests.
SystemLogger "is an easy to use, very lightweight, and highly configurable object logging framework." It failed to install from the catalog browser but loaded successfully using a Gofer snippet. Every class has a class comment. 17 of 19 tests passed, with 2 failures.
Toothpick is a port to Pharo of the Smalltalk library written to run on Dolphin, Squeak, VisualAge and VisualWorks. Documentation on the original site looks good. 16 of 19 tests passed, with 1 failure and 2 errors.
Tags: DevOpsAutomating web content deployment with Fossil
Update Mar 2021 - This blog now uses Fossil's newer hook mechanism. The HOWTO described in this post is obsolete.
I've migrated this site to Pharo 5 from Pharo 3. One notable behind-the-scene change is that content is now deployed using Fossil, the "simple, high-reliability, distributed software configuration management system". Fossil is usually compared with DVCS such as Git and Mercurial.
This server runs the published version of this site. (Of course.) The development version is on my laptop. Now, when I wish to publish changes from my development version, say, when I have written a new blog post, I 'fossil commit', then 'fossil push', whereupon the new blog post and associated artefacts such as images are deployed into the published version on this server.
There are any number of articles on the web describing using Git hooks to automate deploying web content. In this post, I describe using Fossil to do the same. Some familiarity with Fossil is assumed.
HOWTO
To begin, build Fossil with TH1 hooks and Tcl integration. Deploy it both locally and on the server, by copying the single Fossil executable to appropriate directories.
Create a new repostory locally. Take note of the admin user ID and generated password. Let's assume that the admin user ID is 'laptop-user'. Be aware that Fossil has its own user IDs, passwords and roles, distinct from the underlying operating system's.
laptop% mkdir ~/repo
laptop% cd ~/repo
laptop% fossil init webtree.fossil
project-id: 3c05c3016eeabf8e87816ee218c6a86d3c87b950
server-id: ff42bc86dba1a26b1d94b64685f7c09d02581617
admin-user: laptop-user (initial password is "1fe2ff")
Check out the repository locally:
laptop% mkdir ~/webtree
laptop% cd ~/webtree
laptop% fossil open ~/repo/webtree.fossil
Add new content:
laptop% cd ~/webtree
laptop% echo "Hello, world, from Fossil." > helloworld.txt
laptop% fossil add helloworld.txt
laptop% fossil commit -m "First commit."
Upon commit, the repository, ~/repo/webtree.fossil, is updated. Note that the repository is a single file that can be copied, renamed, moved to other computers, etc. Let's scp it to our server and set up the following directory structure there. Here I use /x to keep path names short for this post.
/x/
bin/
fossil <= The Fossil executable.
fossilupdate <= Shell script, described below.
webtree/ <= Checked out tree of webtree.fossil.
repo/
webtree.fossil <= The repository.
To populate /x/webtree:
server% cd /x/webtree
server% fossil open /x/repo/webtree.fossil
server% ls -a
./ ../ .fslckout helloworld.txt
The file .fslckout is Fossil's checkout database.
Create the shell script /x/bin/fossilupdate:
server% cd /x/bin
server% cat > fossilupdate
#!/bin/sh
cd /x/webtree
/x/bin/fossil update
^D
server% chmod 755 fossilupdate
Run the Fossil server. Here I use port 8081.
server% cd /x/webtree
server% /x/bin/fossil server --port 8081
Listening for HTTP requests on TCP port 8081
With your web browser, navigate to the Fossil server and login using the admin user ID and password you noted down earlier. Go to Admin > Settings. Disable autosync, enable tcl, enable th1-hooks, and click 'Apply Changes'. Go to Admin > Transfers > Push. Enter below command into the text box and click 'Apply Changes'.
tclInvoke exec /x/bin/fossilupdate &
This sets up the Fossil transfer hook, which will fire after your Fossil server processes a 'fossil push' request.
Back on the laptop, commit another file:
laptop% cd ~/webtree
laptop% echo "Hello again." > take2.txt
laptop% fossil add take2.txt
laptop% fossil commit -m "Take 2."
laptop% fossil push http://laptop-user@server:8081/
password for laptop-user:
remember password (Y/n)? n
Round-trips: 2 Artifacts sent: 2 received: 0
Push done, send: 1075 received: 1199 ip: <server>
The push from the laptop will trigger the abovementioned transfer hook configured in the server's Fossil server instance, which will update /x/webtree on the server. Viola!
Automatically starting the Fossil server
It is often desirable to start the Fossil server automatically upon server startup. On my server, I use daemontools. However, for some reason daemontools' setuidgid program is unable to run 'fossil server' in the correct directory. So I use Ubuntu's start-stop-daemon instead, and this is the daemontools run file:
#!/bin/sh
exec /sbin/start-stop-daemon --start \
-c cms:cms -d /x/webtree \
--exec /x/bin/fossil \
-- server --port 8081
Create a new user, say, 'cms', and set up ownership of /x:
User:Group Dir/File
---------------------
root:root /x/
root:root bin/
root:root fossil
root:root fossilupdate
cms:cms webtree/
cms:cms repo/
cms:cms webtree.fossil
root:root run <= daemontools run file
Link /x/repo into daemontools, and 'fossil server' runs as the 'cms' user in /x/webtree.
.fslckout
/x/webtree/.fslckout is Fossil's checkout database. If your web server serves content directly from /x/webtree, you should configure it to not serve the .fslckout file.
An alternate practice (according to those Git hook articles) is to rsync the content of /x/webtree to another directory, and it is this second directory that the web server reads from. In such a case, it is still necessary to avoid rsync'ing the .fslckout file.
Users in Fossil
As mentioned, Fossil maintains its own user IDs, passwords, and roles. In this post, I assumed that the Fossil admin user is called 'laptop-user' and used it for 'fossil push'. It is preferable to set up a separate lower privileged Fossil user and use that instead.
Tags: content management, DevOps